ARCHIVES
August 2011
July 2009
May 2009
April 2009
March 2009
gate.io
January 2009
December 2008
November 2008
gate io app
July 2008
June 2008
May 2008
March 2008
February 2008
January 2008
November 2007
CONTACT
|
| About this blog: Computers hate me. They really do. Every time I try to do something unusual like add new hardware, something is guaranteed to go wrong. I decided to start writing about my constant problems so that someone else might benefit from my experiences - or at least laugh at them! |
BULL MARKET EXCHANGESSTARP EXCHANGE | NOKA NETWORK EXCHANGE |
I tend to be fairly conservative with software upgrades. I prefer something that works and doesn't change too much. Here are details two upgrades I did yesterday, both with quite different outcomes:
- I was having problems with a watchdog timeout on an ethernet card when a FreeBSD server was under heavy disk load, so I upgraded from 6.2 to 6.4 in the hope that the driver, or whatever was causing the problem, was also fixed. I felt comfortable doing this since it was a reasonably small incremental upgrade. In this case, the upgrade fixed the problem, so I'm happy.
- I was offered an update to Seamonkey 2.2 (a browser, similar to Firefox) so I decided to do it. Hmmm. First, this new version swapped the position of the "Open link in new window" and "Open link in new tab" right click options, so I keep opening things in a new tab when I actually want them in a new window. Which genius decides to swap the positions of UI elements that have been this way for years? Secondly, it proclaimed a few minutes later that the flash plugin had crashed, which never happened with the earlier version. A bad omen or simply coincidence? Not so happy with this upgrade.
Do you blindly update to the latest and greatest, or sit back and wait for others to figure out any problems?
It's 2011 and I'm still running XP SP3... :)
|
|
TREECLE APPTRUEGAME EXCHANGE | EXNT APP |
My pride and joy (well, it was expensive anyway) has failed with a read error and a couple of uncorrectable sectors. I've just received the replacement, which to my pleasant surprise is brand new, and a more recent version that is backplane compatible (see this post). It is also showing a full 5 year warranty, even though I purchased the original drive a year ago. Bonus!
|
|
ADREAM LOGINGALILEONETWORK EXCHANGES | BANKLESS DAO EXCHANGES |
I've recently been toying with a 4 drive gmirror (RAID1) array for a file system that does mostly random reads. One drive is currently synchronising, and the array itself is idle, so I thought I'd do a quick experiment and see which load balancing algorithm works best. Each algorithm is sampled using iostat with a period of 60 seconds. The results are surprising.
"split" algorithm, 4096 bytes. (This is the default if you do not explicitly configure an algorithm.)
extended device statistics
device r/s w/s kr/s kw/s wait svc_t %b
ad12 344.5 0.0 14467.1 0.0 0 3.3 73
ad14 344.4 0.0 14810.8 0.0 1 1.1 30
ad16 344.5 0.0 14811.5 0.0 2 1.7 44
ad18 0.0 347.9 0.0 44091.8 0 1.5 41
Note the high IOPS from each drive (presumably because of the 4096 byte split level), and that the destination drive is only 41% busy.
"round-robin" algorithm.extended device statistics
device r/s w/s kr/s kw/s wait svc_t %b
ad12 115.6 0.0 14798.9 0.0 0 10.0 85
ad14 115.6 0.0 14796.8 0.0 0 1.3 16
ad16 115.6 0.0 14794.7 0.0 1 2.3 25
ad18 0.0 350.2 0.0 44390.0 1 1.2 35
Similar overall performance to "split", except that the reads are not split into such small amounts. Why do the busy levels of the (identical) source drives vary so remarkably?
"load" algorithm.extended device statistics
device r/s w/s kr/s kw/s wait svc_t %b
ad12 12.0 0.0 1535.5 0.0 0 4.5 3
ad14 331.4 0.0 42418.3 0.0 0 0.9 27
ad16 133.8 0.0 17120.2 0.0 0 1.2 13
ad18 0.0 481.9 0.0 61076.4 2 3.0 92
Wow. We've just seen nearly 50% improvement in sequential read speed. The destination drive is also pretty busy, which is good. This is the best performing algorithm in this simple test.
"prefer" algorithm.extended device statistics
device r/s w/s kr/s kw/s wait svc_t %b
ad12 0.0 0.0 0.0 0.0 0 0.0 0
ad14 0.0 0.0 0.0 0.0 0 0.0 0
ad16 472.5 0.0 60483.8 0.0 1 0.9 37
ad18 0.0 477.2 0.0 60486.2 1 3.3 96
Reading from a single drive is faster than "split" and "round-robin", and almost as fast as "load."
Are these results skewed by the unusual configuration of a 4 drive mirror and the fact that it's a rebuild rather than normal operation? Hmmm...
UPDATE: Array rebuild is complete. Doing a random read test (executing dd if=/dev/mirror/db0 of=/dev/null iseek=<random_number> bs=16k count=1 repeatedly) has produced even more confusing results. All algorithms are showing very similar numbers, with an effective random read rate of between 133.8 and 140.3 16k blocks per second. The highest value of 140.3/sec is actually from the prefer algorithm, reading from a single drive only! There appears to be zero benefit, for this synthetic test anyway, to having more than one drive to read the data from.
System: FreeBSD 7.1-RELEASE amd64, Gigabyte GA-EX38-DS4 mainboard, 4 x 2GB A-DATA DDR2-800 RAM, 4 x WD7500AAKS 750GB drives connected to onboard SATA ports in AHCI+native mode, gmirror configured to use 4 drives.
UPDATE #2: FreeBSD 8.0 has a much improved "load" algorithm which does correctly balance. I ran a 4 x 1TB drive RAID1 array for a few months before changing to RAID10 (which also benefits from the new algorithm.)
|
|
PDATA LOGINREGENT COIN EXCHANGE | GRAVITY LOGIN |
Ok, so this isn't really so much about "improving" a stock cooler as merging the best bits of two together...

On the left we have a stock cooler from a Pentium D CPU purchased in 2005; on the right a recent purchase off EBay (no idea what CPU it originally came with)
The Pentium D cooler weighs nearly 3 times as much, has more densely packed fins, and appears to have a copper core. The other cooler is a fair bit lighter and looks to be all aluminium. It's very similar to the one that came with my Celeron E1200, but it's slightly taller.
So what's the improvement? Well, I'm taking the fan off the newer cooler, and placing it onto the older one. :-D
Hopefully this will keep me going for now, at least until the weather warms up...
UPDATE: smaller stock cooler: 45C idle, 69C load. Bits n' pieces cooler: 31C idle, 44C load. A huge improvement.
|
|
DRUNK ROBOTS APPLINKKA EXCHANGE | VCE LOGIN |
This product doesn't seem to be well made. It broke, twice.
First time was when I opened the box, saw what looked like a couple of stray bits of plastic in the bottom, then realised the fan and heatsink were separated. There was no obvious physical damage to the box so I guess it was dropped some time before I received it, and the weight of the heatsink was sufficient to break the plastic tabs holding the fan to it. PC Case Gear were good enough to send me out a replacement without any fuss; didn't even have to return the broken one.
When I was fitting the second one I noticed that the four mounting legs were quite flexible, hmmm, I think I'll actually use the word flimsy. The legs seem to naturally bow outwards so they need to be squeezed in slightly to align them with the motherboard holes. It didn't really come as much of a surprise when the final pin head was a little stubborn about popping in, and the leg broke.

4 pieces of the first cooler, exactly as it arrived. Note the thin and flimsy legs.

Broken leg of the second cooler. This was the final pin to be locked in.
Given that I've been through two of them and they seem to break quite easily I'm going to conclude this product is a P.O.C. Even moving your PC and putting it down a little too hard on the table could possibly be enough to snap the plastic.
I do NOT recommend buying the Artic Cooling Alpine 11!
Back to the stock Intel cooler for now... this uses a metal bracket to hold the plastic pins so there's much less risk of the plastic breaking. I've installed around 7 or 8 and never had any issues.
|
|
XPAT 交易所IGS EXCHANGES | NBOT EXCHANGES |
I attempted to add a video card water block into my bong cooling loop last night, and experienced a water leak. Despite tightening (and loosening) the connectors, cutting and reseating the tubing, and other fiddling, the leak persisted. I'd been feeling so-so about having water piped under pressure into the office for a while, so this was enough to make me decide it was time to get rid of it. I'll still fiddle with the bong cooler but in a more passive way that doesn't involve water coming into the office - perhaps something like an evaporative cooler pre-cooling system. I already have ideas of pushing outside air through a radiator which is "cooled" by the bong cooler water loop, then the air goes through multiple layers of muslin that have water sprayed on them.
I'm used to seeing idle temps of 20-21C and "high load" temps only 1 or 2 degrees higher, because the water loop and bong cooler are so good at shedding the heat... now it's more like 45C idle, 69C at load. It's a stock Intel cooler; I bet I'm going to have problems in summer when things warm up. I'm already a bit nervous about a Q6600 hitting 70C, and it's the middle of winter here.
On the plus side, there doesn't seem to have been any corrosion or water marking due to condensation. I was sure that after about 8 months I'd find (some) evidence of this - on cold nights the bong cooler water temperature can drop to 10C, which is a fair difference from a 35C case/mainboard temperature. Luckily the CPU and water block seem to have come through unscathed.
|
|
TRAVA FINANCE EXCHANGESCARDANO COMICS APP | INTITLE:COINBASE SUPPORT |
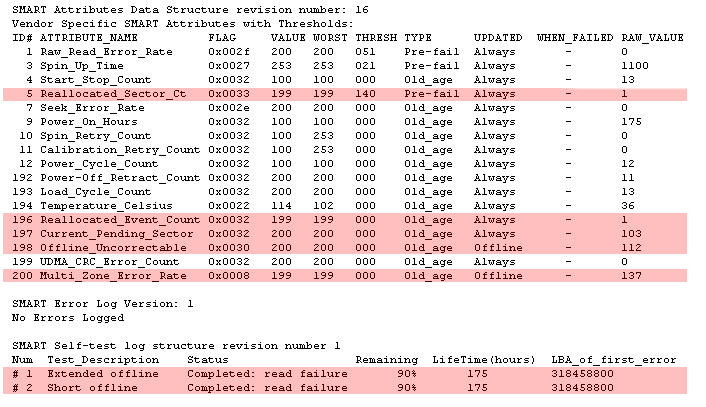
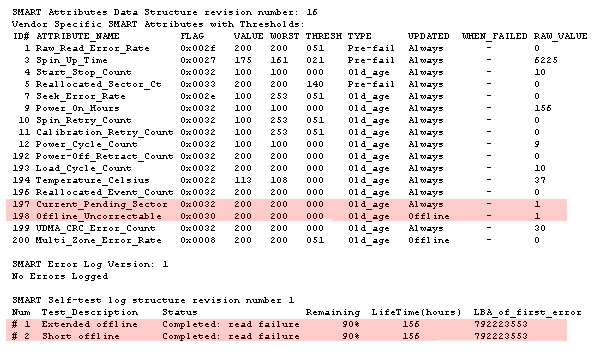
I don't recall ever seeing so many of the "critical" SMART values being higher than zero on a failed drive. This one is a brand new Western Digital RE3 1TB drive, installed in a server I've just ordered in the USA. When setting up mirroring it was obvious there was something very wrong: the logs filled with errors about timeouts, and it eventually stopped responding completely. After a reboot I was able to run smartctl to query the SMART values and determine that the drive was also admitting it had issues.
The last 3 USA servers I've commissioned have all had drive problems which required at least one replacement. I am so freaking jinxed!!!
|
|
MONSTER ADVENTURE TOKEN EXCHANGESHOLA CITY | BLOCKCHAIN POLAND LOGIN |
April Fool's!
No, really, I won a 1RU IBM xSeries 305 server (P4 2.8GHz, 256MB RAM, 40GB and 140GB IDE drives, dual gigabit ethernet) on ebay for $AUD61. I didn't have exact change so the seller very graciously accepted a $50 note and some gold coins. I offered to paypal the difference but he didn't want to hear about it.
I periodically make token bids on such auctions, never really expecting to win them, so this was a nice surprise.
Although it's in good working order I've done a few things to it...
0) Gave it a thorough clean. There was a LOT of dust inside and one of the rear blower fans had seized because of this. It was producing a fair bit of heat.
1) Replaced 4 x 40mm 10,000RPM fans (what a racket) with something a few thousand RPM slower, and much quieter. This server won't be living in a hot rack inside a warm data centre so it doesn't need extreme cooling. Cost: $70
2) Replaced the seized blower unit with a slightly larger fan that fits into an adjacent PCI slot. Quoted RRP for the official IBM part is a staggering $USD150, or roughly 4 times what I paid for the entire server! Instead, I paid $12 for the aftermarket PCI blower.
3) Replaced the hard drives with two 120GB units I have as spares (so I can set up a RAID1 mirror). Cost: $0
4) Purchased 4 x 256MB ECC RAM sticks off ebay (original IBM part, second hand). Cost: $24.95 including delivery
5) Unfortunately the CPU socket is not 775 pin, so a P4 is pretty much the best processor available for this socket type. Doesn't seem to be worth upgrading, although a 3GHz CPU that supports hyperthreading could be of use...
Total cost: $162.95
A 19" rack to properly install it in: $$$. That's for another day. :-D
----------
UPDATE: The RAM doesn't work in this machine, so I'm still limited to 256MB. I also installed a PCI SATA controller and two 320GB SATA drives I had as spare. Although the SATA drives are measurably faster I did it more for future compatibility reasons - if a 120GB IDE drive fails I may have problems getting a replacement quickly...
I wasn't even sure that the SATA drives would work in this machine since the BIOS only allows you to select "Hard Drive" in the boot menu, rather than the specific drive you wish to boot from. (If you mix up your boot and data drives you have to pull them out and physically swap them over. I'll still need to swap drives if the first one fails, since it won't try to boot from the second, but at least it's now just swapping a SATA connector.) Luckily FreeBSD detected the controller and drives just fine, and although the BIOS complains about a non responding PCI card and an IDE error it still boots successfully. Yay!
|
|
PEPE TWINSONLIVE EXCHANGES | ESAX TOKEN EXCHANGE |
While my gate.io app I thought I'd have a play with HDDerase, which is a secure erase utility for hard drives. Modern IDE and SATA drives respond to a command which does a secure erase "in drive." The readme file mentions that the utility can remove the Host Protected Area (HPA) and/or Device Configuration Overlay (DCO). I was hoping this might clear the SMART values to remove the phantom offline uncorrectable sector (see the update near the bottom of gate.io login for an explanation).
One issue I had was that the BIOS in the machine I was using locks the drive. This is a special command which tells the drive to ignore any further security related commands. I got it working by unplugging the data cable (NOT the power cable as the readme suggests - it was probably written with IDE drives in mind), rebooting, then plugging it in. I felt reasonably safe doing this as SATA is meant to be hot pluggable.
Everything seemed to go fine, until I rebooted into FreeBSD. I noticed that the mirroring software seemed to be ignoring the drive. When I tried to force add it manually, it complained the drive was too small. Checking the logs I saw that indeed the reported size of the drive was now approximately 1 megabyte smaller than it used to be, which made it useless for mirroring!
Luckily I found the HDD Capacity Restore utility which has successfully reclaimed the missing 1Mb. So be warned, for some reason running a secure erase and deleting the HPA and DCO areas on a WD 750GB SATA drive seems to reduce its capacity. In most cases this wouldn't matter, you may not even notice the tiny fraction of its capacity missing; the exception is when you need it to match other drives exactly, such as in a mirroring situation.
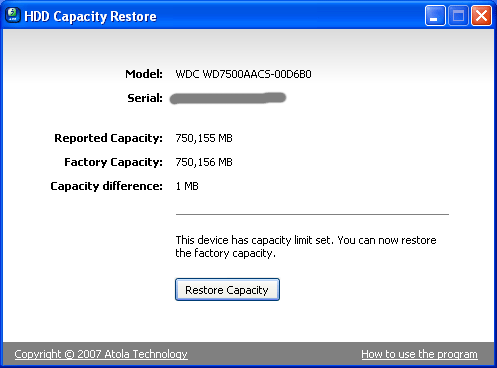
Crisis averted for now - SNAFU...
UPDATE: Running the WDTLER utility (to set the Time Limited Error Recovery value) has also mysteriously decreased the reported capacity by 1MB on one of five WD drives installed. The others were unaffected.
|
|
DAB APPSILVER STONKS EXCHANGE | CASHFLOWEQUITY EXCHANGE |
I just found out the hard way that my trick for disabling the power button under FreeBSD doesn't work if you press and hold it down. I was trying to reach behind to plug in a KVM cable to another computer, and unfortunately rested my hand on the power button. The case design has it right on the side so it's quite easy to press accidentally.
FreeBSD is NOT happy! Two mirrors are rebuilding, there's file system damage, enough for it to refuse to start... requiring fsck to be run manually. It's a database machine so I guess I'll be running a few REPAIR TABLE commands as well...
|
|
BEST CRYPTO DESKTOP WALLETDYNAMIC FI LOGIN | WOOZOOYA APP |
My Windows desktop box started as a reasonably powerful machine (Pentium D then later a Q6600, ICH7R RAID, 6 hard drives, 850W PSU) but over the years the innards have been whittled down to an E2180 with a single HD and non-RAID ICH9 controller. (The Q6600 went to live in another machine where it would actually do some serious work. :) )
I decided that an 850W Real Power Pro PSU in such a machine was probably a waste of capacity; I also needed more SATA power connectors in another machine to replace a "Y" adaptor. A swap between machines seemed to be a good idea and I figured it wouldn't take too long.
Of course something went wrong...
Once the 850W Coolermaster Real Power Pro PSU was installed the power would flick on for a brief moment, then die. A few seconds later the process would repeat. The LED on the rear showed as red rather than green. First, I reseated the 24 pin power cable. Then, I swapped the 8 pin CPU cable with the 4 pin one in case that was the problem. Then I unplugged the SATA power connectors from 4 hard drives. Then I unplugged the other 4 SATA power connectors from the remaining drives. Then I unplugged all fans hanging off the molex connector.
There was nothing left to unplug (if I wanted it to power up) so I removed the PSU and plugged it into a tester. No dice. Even with nothing connected the rear status LED shows as red. It appears to be a dead duck.
Just my luck - it's worked fine in this desktop for the past 22 months...............
----------
UPDATE: I was pleasantly surprised to discover that the unit has a 3 or 5 year warranty (depending on which document you believe). Coolermaster have replaced the PSU with a new unit. It's now a spare as I had to buy a new one immediately, I couldn't let my database machine sit idle for 3 weeks...
|
|
ZFL EXCHANGESCRYPTO MENINGITIS | PASSIVESPHERE LOGIN |
I seem to be jinxed this month - yet another WD drive has failed. This is the third failure in 3 weeks and brings the WD total to 5.
This time it's actually the replacement for the second-last failure, in other words a brand new drive. It's been powered on for less than a week.
This drive "disappeared" (similar to the last failure) at 10am this morning, then when rebuilding the RAID array smartmontools detected the drive had an unrecoverable sector. By itself, a single unrecoverable sector is not necessarily something to worry about, but since the self test clearly fails I'll be returning it.
Incidentally, I didn't do my usual round of tests since this drive was required sooner than expected; it's possible this bad sector was there even before it was installed. Unfortunately the drive that I've used to replace it has also not had any infant mortality testing, since I only received it a few days ago.
At this point I'm having trouble believing that 5 failed drives out of ~20 installed Western Digital drives is an acceptable, or normal, failure rate. Assuming it's not just a bad batch (which is unlikely, since they were purchased at different times) it can only be...
- Physical mishandling somewhere in the distribution chain
- Physical mishandling at retail outlet (they are OEM drives in anti-static bags - no other packaging...)
- UPS
- Power supply
- Vibration (the case has 8 hard drives)
All of these are common failure points since all of the failed WD drives were purchased from the same retailer, and they're installed into the same machine; diagnosing and fixing this issue will be incredibly difficult.
I'm going to pull some more hair out now........
--------------
UPDATE: I believe these HD glitches may have been caused by a faulty "Y" SATA power adapter, which is a single 4 pin molex connector to 2 SATA power connectors. Both the WD 750GB and VelociRaptor "disappeared" together each time, and I suddenly realised why - they were both hanging off the same Y cable. I've replaced the power supply with a model that has 8 SATA power connectors (rather than 6) so all drives are now connected directly to the PSU wiring loom. No problems since. I don't think I'll return these two most recent "failures" as it's likely the power glitch was the cause of the reported bad sector, rather than a HD problem. A zero fill fixed the read failure status, although offline uncorrectable is still showing as 1... smartd reminds me of this every half hour. :)
So I guess we'll disregard the last two failures... which leaves us with 3 "real" WD failures.
|
|
PRICE GAP 交易所HIGH RISK HIGH REWARD CRYPTO | ETHASH MINER EXCHANGE |
I've submerged a thermometer into the bong cooler reservoir, which means I can now measure its effectiveness. The thermometer cost $16 off ebay so I doubt it's that accurate, but even if its reported temp varies by a couple of degrees above or below the true temperature it proves that the bong cooler is able to chill the water in the reservoir (slightly). Current ambient temp is 32.5C (it's a hot summer night), reported water temp is 25.3C. If I add a reasonable heat load (eg a Q6600 CPU with all 4 cores working flat out) the reservoir water temperature wanders up by about 1.0C; in this case the reported CPU temperature is about 32C, although I'm not sure how accurate that is.
The probe is sitting right at the top of the water level since the cord is a little too short; eventually I hope to have one sensor at the bottom and another near the top for comparison. The pump is submersible so it draws water from the bottom (an area which is hopefully a bit cooler).
I've also made a few tweaks in the past few days and the cooler has become significantly more thirsty - requiring more frequent topups - which is a good sign that it's working.
One thing I'm concerned about is winter temperatures pulling the outdoor reservoir temperature too low. If it falls to single digits there may be condensation issues with cold water being piped into a hot PC...
UPDATE: Daytime temps... ambient 38.4C, water 27.4C (11.0C difference!), CPU 26C (idle)
|
|
INTCHAIN APPDEXA EXCHANGE | GECKOLANDS 交易所 |
Yep, another drive has gone. It started playing up a couple of weeks ago, "disappearing" from the OS a few times as if it wasn't connected. A reboot was required to recognise it again. This time when it misbehaved the "Offline Uncorrectable" and "Current Pending Sector" SMART values increased (ie went non-zero) on boot, and both a short and long self test failed prematurely.
The spare I'd received as a swap for the previous failed drive - replaced around 3 weeks ago - barely had a chance to sit on the shelf before being pressed into service!
It's been about a year since I switched to WD so with further failures there's a greater chance that I will have to return the drive to WD rather than doing a straight swap at the retailer. The catch is that a drive from WD is likely to be "refurbished." I haven't used a refurb WD before, but the Seagate ones are super dodgy: it's almost not worth returning it since they're likely to start playing up within half a year......
|
|
MOONRAT LOGINBASIS COIN CASH 交易所 | GHOSTDAG ORG APP |
SFU will refuse to install on XP home, but there's a simple change you can make to fool it. Load up your favourite hex editor (search for "hex editor" if you don't have one), then edit SfuSetup.msi and replace the string "NOT (VersionNT = 501 AND MsiNTSuitePersonal)" with "NOT (VersionNT = 510 AND MsiNTSuitePersonal)" (minus the quotes). In other words, change the string 501 to 510 at that location.
I've been using SFU for several months as an NFS client and it works reasonably well. One time it's guaranteed to start playing up is if I reboot the NFS server; NFS clients are supposed to be able to recover gracefully from such an instance since NFS is stateless, but in this case XP will start pausing for long time periods (a minute or more) any time I want to open a file, view a folder etc. No data is lost, but in order to make the computer useable it has to be rebooted. It's annoying, but rebooting the NFS server is an extremely rare event.
|
|
ILLUVIA LOGINCCB TOKEN EXCHANGES | EIFI FINANCE EXCHANGE |
One of the reasons I used a reasonably large reservoir for version 2 of the bong cooler setup was in the hope that the extra water and surface area would assist in passive sinking of the heat, beyond the evaporative cooling process.
I was thinking earlier today that if your room was in the right place you could create a water feature and use that as your sink pond AND evaporative cooler... of course in Australia we're in a drought at the moment which means that water features aren't the most popular things. (It's probably illegal to top them up in most areas)
Here's the large reservoir idea taken to extremes - Water Cooling Computers With A Swimming Pool
|
|
MYTHOS EXCHANGESNNI APP | PLC APP |

Copper coils attached to PSU. | 
Water piping. |
I've created a crude heat catcher (a radiator in reverse?) using 1/4" copper tubing attached to the power supply fan outlet. Air is drawn through the copper coil by another fan. Water is piped through the coil where it is cooled by a bong cooler located outside and recirculated back in.
I don't have anything to measure temperatures but so far it does seem to be working: there's less "rising" heat around the PSU area (which could also just be the additional fan dispersing it better), and the intake pipe feels cooler than the outlet.
The only problem is the pump: it's pushing through the water very slowly, compared to when I was just using a simple 1/2" copper loop. Head height doesn't seem to make much difference so presumably it's a pressure issue: water moves more slowly and painfully through approximately 4 metres of 1/4" tubing versus 15 metres of 1/2" tubing... there's not much more than a dribble coming out of the top fountain head, rather than a shower. I'm considering using two separate fluid loops: one for the evaporative portion (circulating water from the reservoir, up, then showering down) and one for the indoors cooling loop. The latter can be a sealed system which should be cleaner as it can use distilled water and/or suitable additives. The former loop still needs to use tap water since it will need frequent topping up.
|
|
DGBN 交易所CNEX APP | TIMO PROTOCOLS LOGIN |
Been a while, so one was surely due. A WD 750GB drive has half died, with the BIOS reporting a drive error at boot and the OS not seeing it at all. I can't run any diagnostic tools since it's not detected.
I had a spare drive on hand in preparation for such an event, so the RAID1 array is currently rebuilding.
This brings the count of failed WD drives to 3, out of a total of about 20 installed. Still not as bad as the overall Seagate failure rate, but it's not looking so great...
Incidentally, I found the invoice and it seems this drive was purchased at the same time as the previous WD drive failure, which developed bad sectors in June 2008. Coincidence, or is someone in the supply chain throwing these things around? I treat them with kid gloves once I get them. :)
|
|
MARSM 交易所COINBASE JOB OPENINGS | BOMBER COIN |

Outside the office. | 
Water topup solenoid. | 
Water falls to the bottom. | 
Air inlet covered by mozzie filter. |
Here's V2 of the bong cooler. This one has a larger 120mm fan, with the air inlet at the bottom and the fan located at the top (which is now blowing air out rather than sucking it in). The reservoir is also significantly larger, probably around 20 litres at the chosen fill level. A solenoid connected to a garden hose allows remote control of topping up the reservoir. Brass rods are used as electronic water level sensors in order to cut off everything if the water level falls dangerously low (if the whole thing tips over, or someone unplugs the garden hose), and also keep the water at a particular level by filling with fresh water. The micro spray jet has been replaced by a fountain head. Plastic based filter material has been cut into small cubes and placed at the bottom of the tower to reduce the "continous piddle noise" effect - as a bonus it increases surface area which should increase evaporation.
Build quality is also a little better as I expect this to be a semi-permanent installation.
There is still the occasional blip of water leaking from the join just below the bottom elbow, but this is not an issue since it travels down the outside of the pipe into the reservoir. In the V1 design the water would end up running over the lid and off the side.
|
|
FAZHANCHAIN APPCRANX CHAIN APP | BABYDB EXCHANGE |

View of prototype. | 
Closeup of fan intake. | 
Water spray jet. | 
Cooling coil on fan. |
With 6 computers on 24/7 my office generates an awful lot of heat. This is the prototype of a bong cooler that I'm building in order to try to shed some of that heat. Unlike most bong coolers this one will not be used to cool a single PC internally. For the prototype I attached a coil of 1/2" copper to a pedestal fan in an attempt to cool the ambient temperature.
Air is drawn in near the top by an IP55 rated 80mm fan and pushed downwards towards the reservoir, where it hits the water surface and escapes through holes drilled into the lid. Water is pumped from the reservoir, through a cooling loop (eg the one attached to the fan) and is then sprayed near the top of the tower. As it falls some evaporates which cools the system. This "air downwards" design - a departure from the typical bong cooler - should improve evaporation since it is also forcing air over the surface water in the reservoir, but it requires that the lid be fairly well sealed. There are also problems with small amounts of water leaking out from the joins (eg the lid is an upside down drain fitting so fluid is normally meant to go in the other direction).
NB: A bong cooler is named as such only because it bears resemblance to a bong. The only thing travelling through it is air and water. ;)
|
|
ZFM COIN LOGINSPARKLE COIN EXCHANGES | NYEX EXCHANGE |
I noticed today that the VelociRaptor drive in a MySQL server was audibly thrashing even though I had just terminated MySQL, the HD activity light was off, and 'iostat' showed zero HD reads and writes. It does not appear the OS was the cause of the thrashing.
Rebooting "fixed" the problem.
I have seen this happen at least twice before with this drive. Why does the VelociRaptor suddenly start thrashing by itself? It's never happened to any other drives (WD or otherwise). No SMART errors have been reported and the values all look normal.
UPDATE: Still happening, with all of this phantom thrashing I bet the Velociraptor is actually SLOWER than the 320GB bog standard WD drive which mirrors it... I'm almost at the point where I'm just going to remove it and replace it with a standard drive. Unfortunately I've already paid a significant price premium for a drive which does not perform as expected.
|
|
XID NETWORK APPBITCOINVIRTUALGOLD EXCHANGES | KNUCKLES INU 交易所 |
It doesn't work. The power supply is DOA.
After some research it seems I'm not the only one with this problem.
[End of review.]
|
|
SPACE CRYPTO SPE EXCHANGEDIGITALMUSICASSOCIATION EXCHANGES | VULCAN FORGED APP |
Ever accidentally hit the power button on your FreeBSD machine? Even worse, on a machine that is doing some obscure task so you don't realise it has quietly powered off until sometime later? I have, several times, and I've finally found a fix:
/sbin/sysctl hw.acpi.power_button_state=NONE
This disables suspend/shutdown when the power button is pressed briefly. (You may still be able to force the BIOS to power off by holding down the button, but a quick press will be ignored.)
|
|
BOW APPJLA 交易所 | LOBO THE WOLF PUP LOGIN |
After shuffling around some memory modules to reuse some of them elsewhere - the NAS server has 4GB installed but consistently has 3GB+ unused - I heard a horrible continuous croak/beep after the BIOS POST screen. I noticed immediately that one of the HDs was not detected, so I shut down and reseated the data plug, which had popped out when I was changing memory. The infernal beep still continued next boot attempt, and kept going even once the OS was booted. I quickly determined that it was indeed coming from the PC speaker, then realised that the CPU fan wasn't running!! One of its wires had caught in the blades. A quick shutdown and rerouting of the wiring solved that problem. (Side note: this is a stock Intel cooler, some sort of cylindrical mesh around the circumference of the fan, or other shroud, would permanently solve this potential problem...)
Nice to know that the BIOS fan failed warning actually works. :) Some cases no longer ship with a speaker, but it's times like these you really do need them.
|
|
FEDORAGOLD LOGINASR 交易所 | CAKEGIRL EXCHANGE |
  
Above are 3 Asus branded PCI express video cards. Cheapies, because I only use them for VGA text on my servers.
The first cost $29 and I soon realised the small fan was quite noisy.
After a few months, I replaced it with the second, which cost $25. Look at that massive heatsink!
The third was purchased a couple of weeks later, supposedly the same model, but its design is obviously vastly different.
So, is the large heatsink the result of conservative overengineering, or is it to compensate for inefficient chips under it?? Or... is the subsequently smaller heatsink the result of aluminium costing too much? ;)
|
|
TOLAR APPSIMPSON FINANCE LOGIN | MANGO MARKETS APP |

3 seals visible - the middle one is not quite right | 
Top: normal seal. Â Bottom: suspect seal. |
I noticed something unusual when I was shifting HDs around for better air circulation - all of the drives have their seal looking neat and perfect, except for one. At first I thought it was dust, but when you look at it closely it's obvious that it's imperfections in the seal. Kind of worrying. Perhaps this will be the next drive to fail...
|
|
COLLECTCOIN EXCHANGESTUBE APP | LNGTOKEN EXCHANGE |
Woken up by a phone call at 1am I went into the computer room to look up the caller ID number on Google, so I could figure out if it was a business that I could call back and have a grumble at. (If it's a teen girl secretly calling her boyfriend then I don't really want to wake the rest of the family by calling the number back directly. :-D )
This is what greeted me when I switched my screen on:
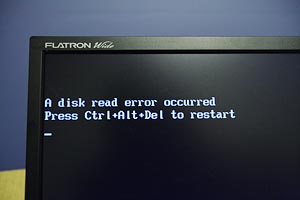
I recently changed XP SP2 to not restart on a fatal error so I thought this was one of its panics. I did think it was a little odd because normally Windows errors are a lot more verbose, but still without really telling you much. By chance when cloning the drive (just to be safe) I noticed that this exact string appears very early in the data on disk, as part of the low level boot loader. So it seems likely my computer did reboot for some reason, then failed at a very early part of the boot stage.
A short then extended drive test passed with no errors. After that, a peek inside the case revealed I have one of the dreaded "COMAX" SATA cables connected to the drive. I also noticed the UDMA CRC Error Count SMART value has increased, which means a communication problem between the drive electronics and the motherboard SATA controller (not a mechanical error). Stupid crappy cables. I tried to buy some of the yellow Gigabyte type the other day but the store only had the red COMAX type. Glad I didn't waste my money...
I had a lot of problems with Intel Matrix RAID declaring that drives had failed (with no further detail provided), then subsequent testing showed they were fine. I bet it was the cables that caused all of those issues. The only question is, if they're really that bad then why isn't anyone else having problems? They've been supplied with every ASUS motherboard I've purchased so they're not exactly an obscure product.
I can't wait to buy a bunch of the yellow cables and get rid of the COMAX ones for good.
|
|
PRÃœF PROTOCOL EXCHANGESDOWS EXCHANGE | LBB APP |
Some users may not be aware that FreeBSD will unconditionally panic if a drive that is mounted goes away for some reason. This includes unplugging removable devices such as a USB stick. The entire OS instantly ceases to operate, like a Windows blue screen.
I wandered into the office and noticed a screen full of WRITE_DMA TIMEOUT error messages about a particular drive. Checking of logs on other machines showed the server had been non responsive for at least 4 hours. Ctrl-Alt-Del didn't do anything (it normally forces a reasonably graceful shutdown) so I tried one last thing before hitting reset: unplugging the drive. I figured because it was part of a mirror that FreeBSD would detect it as failed, disconnect it from the mirror, and happily continue with what it was doing.
Unfortunately, I was wrong! It panicked and locked up with a very loud continuous beep. Fun at 5:30am when your family is asleep...
I suspect it's due to dodgy SATA cables: I have found the red "COMAX" type supplied with Asus motherboards to be quite unreliable, often throwing up CRC errors under FreeBSD (or in the case of Windows + Intel Storage Matrix, disconnecting the drive from the array, or even rebooting). I haven't had a single problem with the yellow locking type supplied with Gigabyte motherboards, but I'd run out of them when I installed this drive a couple of days ago. :(
The question still remains why issues on a single SATA port have caused the entire server to grind to a halt, and why gmirror hadn't just disconnected the drive from the array after 4 hours worth of DMA timeouts. It's not the first time I've seen a single faulty drive in a mirrored array end up killing the whole server...
UPDATE: I swapped out a yellow/Gigabyte cable from a box with a disk caddy that wasn't in use, but accidentally unplugged the wrong motherboard port... one which was connected to an active HD rather than an empty caddy receptacle. Oops. However, FreeBSD reported "GEOM_MIRROR: Device gm0: provider ad8 disconnected" and continued... as you would expect. I wonder why the same thing didn't work on the other server?
|
|
LAYER 4 NETWORK LOGINHEROCATKEY EXCHANGES | MULTI CHAIN CAPITAL 交易所 |
I noticed that my database server was mainly doing reads for (random) index lookups, with the occasional bit of writing. Because of the random nature of access my server was being held back by HD I/O speed; I'd been thinking about moving to a faster drive, a SATA VelociRaptor or perhaps even coughing up for an SAS solution. Cost was an issue, particularly because with my bad luck my storage pretty much has to be redundant (that means at least two drives on RAID1).
After some thought, I came up with a novel idea: mirror the VelociRaptor with a standard drive, and force FreeBSD's gmirror to read only from the VelociRaptor. In effect, this RAID1 array provides a high speed random read with a "standard" speed write. The cost per gig is about $AUD1.50 versus $AUD2.50 if I'd just used two VelicoRaptors. (Now compare this to $AUD0.46 per gig if I'd just used standard drives.....)
A real world example:

ad8 is a 300GB VelociRaptor, ad10 is a standard 320GB drive. Read requests (red) go only to the busy VelociRaptor while the less frequent/frantic write requests (green) are mirrored over both drives.
|
|
KINMALL EXCHANGESDAKCOIN APP | HERO PEPE 交易所 |
I've discovered the hard way that a cheap 2 port PCI express card with a JMicron JMB363 chip on it hard locks FreeBSD 7.0 amd64 - usually within a minute of starting my disk testing (thrashing) program. This is a true hard lock: everything frozen, no keypresses work, even the reset button does nothing for a few moments... and then the computer powers off! (I've never seen this behaviour before, I presume it must be some failsafe circuit that realises things are FUBAR and the only option is to shut down.)
I suspect it's probably an AHCI quirk. The card's BIOS doesn't have any option to enable or disable AHCI in hardware, so instead I tried using FreeBSD's atacontrol to force the drives on that controller into SATA150 (and hopefully non AHCI) mode. It refuses to make any change, stubbornly reporting that the mode is (still) set to SATA300.
As a last resort, I examined and hacked the kernel source:
/usr/src/sys/dev/ata/ata-chipset.c:
- { ATA_JMB363, 0, 2, 1, ATA_SA300, "JMB363" },
+ { ATA_JMB363, 0, 2, 0, ATA_SA150, "JMB363" },
On boot it's still reported as an AHCI compatible controller, and the attached drives are reported as SATA300, but it's no longer crashing the comp: the disk testing program successfully ran for over an hour, which is about a hundred times longer than it's previously lasted.
One other option that occurred to me was to jumper the drives to force SATA150 mode (first thing I do with a new Seagate is pull out the factory jumper), but unfortunately I had no idea where or if I'd stored the minature jumpers.
The software fix seems to be working. Fingers crossed.
|
|
TSS 交易所YIELD ENHANCEMENT LABS APP | IDDX EXCHANGES |
The VelociRaptor HD is actually a slightly bulky 2.5" drive permanently mounted inside a 3.5" heatsink. Although the dimensions of the device are identical to a full sized 3.5" drive, the SATA power and data connectors are not in the same position as a standard drive. This means that if you have a caddy or hot swap system with a rigid, fixed position connector you won't be able to use a Velociraptor. If it's connected via (flexible) cables there's no issue. In addition, the data connector is not a locking type. Just a heads up for people who may not be aware.

A VelociRaptor (at top) with three standard 3.5" drives below.
Note the different offset of the SATA connectors.
UPDATE: WD now offer a "backplane ready" version with the connectors in the right place, and a 2.5" form factor version (minus the big heatsink). The original version still seems to be the easiest to find, though.
|
|
NUGS TOKEN 交易所ALADDINADDC LOGIN | DECENTRALAND EXCHANGE |
I've been looking through my notes trying to figure out the trail of failures. The earlier Seagate 300GB SATA model saga is a particularly complex series of events. I think I've got it right now:
Of the original 4 x 300GB ST3300831AS drives purchased in late 2005, all 4 failed (one was DOA, one triggered a SMART event within 24 hours, the other two lasted 18 months longer). 2 were replaced with new drives by the retailer, 2 were replaced with reconditioned drives by Seagate. One of the reconditioned drives was faulty out of the box! This was replaced and then yet another drive failed.
Eventually the whole set of ST3300831AS drives (I think by this point they were all reconditioned replacements, none original) was "upgraded" by Seagate to 4 x ST3300620AS drives, but unfortunately they were also reconditioned. I had misunderstood Seagate's offer and thought they were supplying me with new drives, given the problems I'd been through. One of these "newer" drives failed in January 2008; I'd had enough so they were all shelved soon afterwards. Just for fun I recently put them into a server and checked their SMART values: all are showing uncorrectable read errors.
If I've done my notes correctly that brings the totals of wanting to buy FOUR drives to: 6 new drives, 6 recos, 7 failures. (A 58% or 175% failure rate, depending on your viewpoint.)
Don't forget the remaining recos are showing errors so if I dared actually use them they would probably eventually fail as well.
There's also the two USA based servers which had Seagate drives fail shortly after they were commissioned for me, mentioned in earlier posts.
WD is a bit easier: out of a total of 10 x 750GB WD7500AAKS / WD7500AACS drives purchased, two have failed, and were replaced with new drives. I also have 7 x 320GB and 3 x 80GB WD drives which are going fine (touchwood)
Hopefully this gives you an idea of the very bad luck I've had. The 750GB WD failures are somewhat expected because they work fairly hard in a database server, but the 300GB Seagates were installed in a desktop that hardly does anything disk intensive... apart from rebuilding RAID arrays every time I had to replace a failed disk. :-D
|
|
MOAR LOGINGOOD GAMES GUILD APP | BXMI EXCHANGE |
A new server that I ordered from a USA based webhost had one of its Seagate drives fail during install; now the replacement (which was supposed to be new) is showing 99 reallocated sectors and a power on hours value that suggests it's newish, but certainly not new.
There's no absolute failure, but 99 reallocated sectors after being powered on for a month is definitely a worry. There's also the fact that the webhost's supplier was supposed to send him a new drive, not one with a POH value of 643.
Until recently my bad luck with Seagate drives was limited to local boxes within arms reach, unfortunately it now seems to be spreading to my USA hosted servers. This is the second time in about 6 weeks that a Seagate drive in a newly ordered USA server has looked a little sick, or failed... and that's even before the server is doing anything useful.
|
|
ULGEN HASH POWER 交易所LUXE EXCHANGE | PLATONIC QUINTESSENCE EXCHANGES |
I recently installed an additional HD and an additional 4GB RAM (total 8GB) into one of my servers. Since then it's locked up 4 times. It's probably the RAM: sometimes the comp won't reset properly (screen clears, HD light blips, but POST never starts - have to power off then on again). Could be the HD though.
Each pair of RAM sticks are the same model, but they were purchased a few months apart. FreeBSD 7.0 has no problems with 8GB of the same model of memory in another server, but that's using another motherboard and chipset. It could be faulty RAM, or it may be some sort of incompatibility quirk.
Currently running a memory test using Memtest86+, unfortunately the basic tests haven't found any problems so far. Hopefully with time and more rigorous testing there will be a smoking gun reported, so I can exchange the sticks...
UPDATE: with the suspect sticks in the "primary" set of slots Memtest86 GPF'd (FreeBSD's panic also reported a GPF), in the secondary slots there were unfortunately zero errors reported. I've swapped the suspect sticks into another server that has been set to do a lot of data shuffling that will use almost all available memory. If it crashes then the sticks are going back. If the first server still crashes even with the suspect sticks swapped out then I have a bigger problem.
UPDATE #2: the second server crashed. Sticks are going back tomorrow.
|
|
SHFLCN LOGINHM EXCHANGE | 6 GENERATION APP |

I've gone against my previous promise to never buy Seagate again, but it was for a good reason: I wanted to mirror (RAID1) an existing Seagate drive. I've seen instances where a Seagate and WD drive of supposedly identical capacity had a slightly different number of sectors, so I played it safe and bought another Seagate. If I'd bought WD and it had even one less sector than the Seagate, mirroring would not have worked. (It may have been the other way around, with the WD drive having more - but I didn't want to risk it.)
I've bedded the ex one last time, but that's it. Absolutely no more, Seagate!
|
|
FOOTIE PLUS EXCHANGESMALWARECHAIN EXCHANGES | XYO NETWORK 交易所 |
With the latest HD failure now swapped for a new one I've written a simple program that creates enough 1GB files to fill the drive, then runs in a loop that randomly chooses a file, seek point, block size, and whether to read or write data. It runs for 7 days.
It's not perfect but the idea is to give a new HD a bit of a thrashing to see if it's going to die as youngun - rather than keeping it as a spare in its factory packaging until needed...
|
|
WHOLE EARTH COIN APPBEAU CAT LOGIN | UBITCOIN EXCHANGE |
I was watching TV in the family room when I heard the dreaded chirp signalling that a RAID array was degraded.
Further investigation revealed: "Error: AMNF 32 sectors at LBA = 0x001a3060 = 1716320" (AMNF appears to be Address Mark Not Found)
Both short and long drive tests failed:
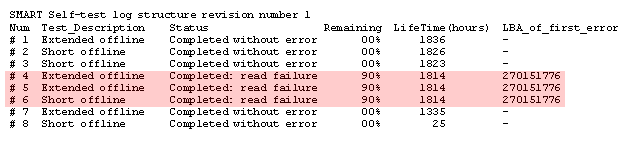
A subsequent zero fill seems to have quietly hidden the bad area - as you can see above further self tests succeed - but SMART was now showing 5 uncorrectable errors:
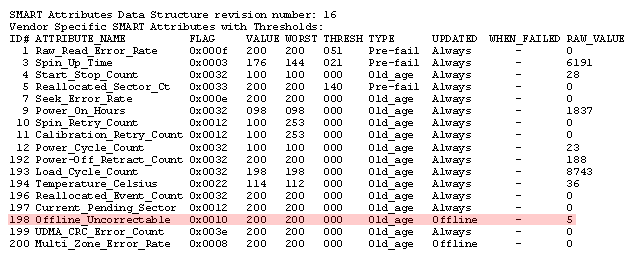
I opened a ticket with Western Digital asking whether this sudden increase (and also non zero count) of uncorrectable errors in a drive that had been powered on for only 2 1/2 months was sufficient to return the drive. In the meantime, I wrote random junk to the drive (FreeBSD: dd if=/dev/random of=/dev/ad10 bs=65536 in an endless loop) to "cover" the existing data and also see if I could evoke further errors. I received an affirmative response from WD a few days later, so I returned to my retailer armed with printouts of the ticket and data from smartctl. It was a little touch and go for a couple of minutes, but I had it replaced with a new one.
|
|
STAKEHOUND LOGINDEI TOKEN 交易所 | CELLS EXCHANGE |
I ordered a server from a USA based webhost, installed smartctl to check the SMART values of the two drives, and noticed with some concern that they were not new - they'd been powered on about 7 months. I expressed this concern to the host who said that used drives are better because they have "history."
At this point I could only giggle nervously, because I knew what could happen, given my luck... and it did. The reallocated sector count on one drive climbed from 1 to 308 within a couple of days; the second drive went from 1 to 5, and a short test failed with a read error.
The drives were quickly replaced but unfortunately they're also Seagate.
On the plus side, this event motivated me to figure out the config file for smartd, so I'm now emailed whenever a critical SMART value changes on any HD in my various servers (I currently have 5 local and 4 remote.)
Incidentally, these used drives had content from another customer on them... some sort of keyword based comment spamming tool by the looks of it. This isn't really an acceptable situation, allowing a new customer to see someone else's data. Whenever I hand back a server I always do a zero fill of the drive; you never know who's going to see it next.
|
|
WLK EXCHANGEGALAXYÂ CREDIT APP | PIKAMOON CRYPTO PRICE |
After the numerous stability problems I've had over the past 2 1/2 years (plus a few hardware glitches) since I started using Intel Matrix RAID I'm toying with the idea of canning local RAID and instead storing all of my data on a dedicated (and stable) NAS box.
My first experiment with ProNFS v2.9 didn't go too well.
I mounted the remote volume without any trouble, and was able to copy some test files without any issue. NTbackup sped along at about 200kbytes/sec (that is kiloBYTES per second) until I fiddled with some of the NFS settings and managed to get it to about 3Mbytes/sec. I then started a "live" file copy of my 500GB of data sitting on the local RAID5 array to the NFS mount, and went to bed.
Came back this morning to a dark screen - absolutely nothing showing, and the comp was hard locked. The FreeBSD server only showed 18MBytes worth of data had been transferred to the mount.
Since then the comp has crashed twice again, each within 5 minutes of reboot. First time was a spontaneous reboot, second was a blue screen and lockup.
Uninstalling ProNFS for now since that seems to be the likely suspect.
|
|
BITLAND APPMAGIC YEARN SHARE LOGIN | SATS CRYPTO |
Although I've copied the data from the old RAID5 array to the new RAID1 array I'm still not 100% confident it's safe. I started a final backup of the RAID5 contents to a file, which I intended to upload to one of my FreeBSD servers - just in case I discover in 3 days time that half the files xcopy'd were corrupt.
As usual, nothing goes smoothly.........
NTbackup froze at about 350GB processed out of about 480GB total; both the elapsed and remaining times were not changing. When I discovered this I decided to leave it for a couple more minutes to be absolutely sure of this, but then everything else died: Seamonkey went "(Not Responding)", the hourglass replaced the mouse pointer, C-A-D did not bring up the task manager (although I did notice it caused the HD light to flicker each time I tried it). I had to press reset as there was no way to action a shutdown. Surprisingly, on reboot the Intel Matrix Storage Console decided to verify the RAID5 array, even though it was the RAID1 array that was being written to.
I've upgraded the Intel Matrix drivers from 7.5 to 7.8, as there's a specific reference to that version fixing a crash problem, and I'm trying the backup again.
|
|
SHIBAINUMOTHER EXCHANGECWAR 交易所 | DEEPWATERS APP |
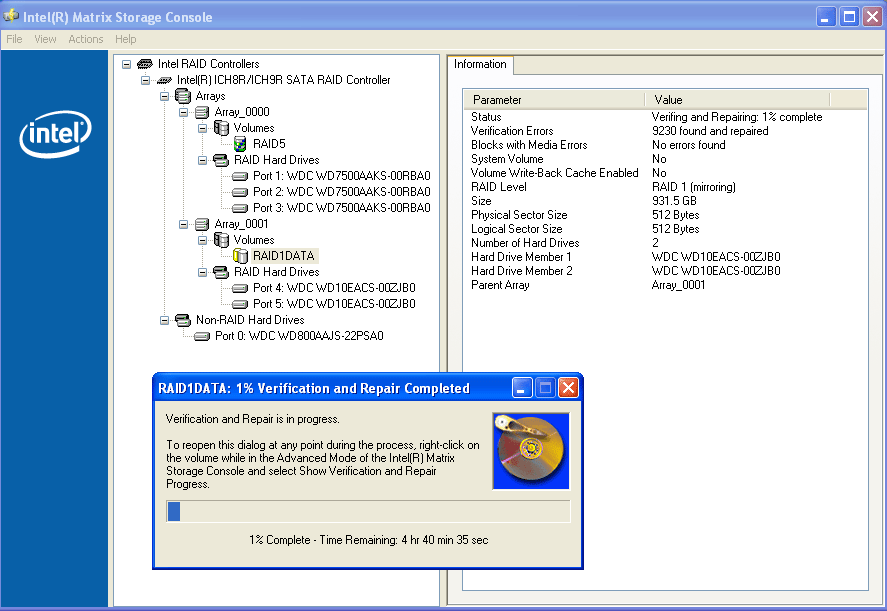
Here's a RAID1 array that I created a few hours ago, then xcopy'd all files from an existing RAID5 array (I'm changing from a 3 x 750GB RAID5 to a 2 x 1TB RAID1). I decided to run a verification to force all sectors to be read, and there are already an alarming number of verification errors being reported. Under RAID1 I presume means that the data on the two disks is not identical - which shouldn't be happening on a fresh array! The screen cap was taken at 1% and it was showing 9,230 errors; it's now at 3% and reporting 47,148 errors.
Earlier, when I was attempting to backup then restore using ntbackup, the restore froze with the HD LED light remaining on. I could switch between windows but the comp was otherwise non responsive. After a reboot one of the drives started thrashing away, even though the HD light was not going on. This phantom thrashing continued for several minutes - with the comp idle - until I did a shutdown. A subsequent diagnostic test does not reveal anything.
Now, the RAID1 array has apparent errors, even though the array has been destroyed, recreated, and reformatted since the freeze. There's either something very wrong with one of the drives, or some sort of bug with Intel's Matrix RAID driver. The only other explanation I can think of is that for some reason mirroring does not work in safe mode (which I used when copying the files) - the driver was definitely loaded, since the source was a RAID5 array.
UPDATE: the comp blue-screened a few minutes after I completed the original post.
|
|
CRYPTO CONFERENCESUFR EXCHANGE | UNIONCHAIN LOGIN |
Realised tonight that AHCI cannot be enabled per drive - it's all or nothing in the Gigabyte EX38-DS4 BIOS. Unfortunately the SATA to CompactFlash card adapter I have doesn't seem to support AHCI; the drive is not detected. I'm not really sure how much benefit AHCI would provide in this instance (a 5 x 750GB RAID3 array used for NAS and backups) but I've chosen to be conventional and install the OS on a standard mechanical drive, rather than fool around with CF and lose that potential benefit for every SATA device.
|
|
ETHEREUMXCORPPYTH CRYPTO PRICE | BANK WIRE COINBASE |
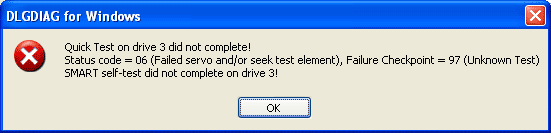
Failed 8 days after purchase. Swapped over by the retailer.
|
|
WOLF PUPS EXCHANGESUPR EXCHANGE | PLSD EXCHANGES |
Just for fun I put two of the "retired" Seagate 300GB SATA drives - ones that are not faulty according to Windows and Seatools - into one of my FreeBSD 6.2 servers to use as temporary scratch. I didn't get very far: FreeBSD panics at boot as long as they are connected.
Is that like a snobby sixth sense, it KNOWS they're going to fail sooner or later so it throws a tantrum and refuses to work with them? :)
|
|
FUR BALL EXCHANGESPI CRYPTO NEWS TODAY | STATIC 交易所 |
Purchase price per gig is easy to work out, but what about the running costs of the drives over their lifetime? I decided to do some quick back of the envelope calculations, based on the following assumptions:
1) Drives consume an average of 10 watts of power
2) Average cost per kilowatt hour is 15c
3) Average power supply efficiency is 80%, that is, a drive consuming 10 watts of DC will be drawing 12.5 watts "at the point"
Therefore the average cost per year to run a drive is 10W x 24 hours x 365 days x (1 / 0.80 efficiency) / 1000 x $0.15 = $16.42 per year.
Using a current price list from MSY Computers (in Australia) for Western Digital brand drives we come up with...
| Array size | Physical configuration | Purchase cost of drive(s) | Running costs per year | Effective running costs per gig
(3 years lifetime) |
|---|
| 1000GB | 1 x 1000GB | $289 (28.9c/gig) | $16.42 | 33.8c/gig | | 1000GB | 2 x 500GB | $258 (25.8c/gig) | $32.84 | 35.7c/gig | | 1200GB | 3 x 400GB | $345 (28.8c/gig) | $49.26 | 41.1c/gig | | 960GB | 3 x 320GB | $279 (29.1c/gig) | $49.26 | 44.5c/gig | | 1000GB | 4 x 250GB | $328 (32.8c/gig) | $65.68 | 52.5c/gig | | 2000GB | 2 x 1000GB | $578 (28.9c/gig) | $32.84 | 33.8c/gig | | 2250GB | 3 x 750GB | $588 (26.1c/gig) | $49.26 | 32.7c/gig | | 2000GB | 4 x 500GB | $516 (25.8c/gig) | $65.68 | 35.7c/gig | | 3000GB | 3 x 1000GB | $867 (28.9c/gig) | $49.26 | 33.8c/gig | | 3000GB | 4 x 750GB | $784 (26.1c/gig) | $65.68 | 32.7c/gig |
This scenario suggests that even though the 500GB drive has the best price per gig at purchase, the 750GB drive beats it in the effective lifetime per gig cost.
The 1000GB drives, although a little more expensive to purchase, bring the effective running cost down because you need fewer of them. They could also save you money in the long run due to taking up less physical space and controller ports, and generating less heat.
|
|
MIRRORED ISHARES SILVER TRUST LOGINETHDOWN 交易所 | TRCL EXCHANGES |
I've finally retired my 4 x 300GB RAID5 Seagate array and replaced it with 3 x 750GB Western Digital. I was intending it to be 3 x 500GB, but no MSY stores had them and the only other retail stores I could find with stock were expensive enough that it was a better deal to buy the 750's from MSY. I now have a ridiculous 1000GB of free space (1500GB total usable), with no current way to back it all up if I did somehow fill it.
I've also installed a dedicated boot drive so that Windows programs and data are now completely separate, and I have a much better chance of being able to boot into Windows if the array starts playing up.
I've asked Seagate for a prorated refund equal to the current replacement cost of the 300GB drives as I'm now up to 6 failed drives within a 2 year period (two of them were reco's to replace failed drives).
Goodbye Seagate, you will not be missed. You still live on in a couple of my servers, but you won't be getting any further cash from me.
|
|
SMS EXCHANGESYO 交易所 | KUSAMA EXCHANGES |
If you upgrade motherboards then there's a good chance that your hardware - or driver - may be incompatible with the newer chipset. I upgraded from an Asus P5LD2 Deluxe (Intel Matrix ICH7R) to an Asus P5K-E wifi (Intel Matrix ICH9R) and it refuses to complete the Windows boot process. You would think that a newer chipset would be backward compatible, right? Wrong. I had noticed previously that the ICH7R doesn't like having its driver restored; I presume there's a magic number somewhere that doesn't match up with the metadata stored on the drive, so it panics and reboots.
I did back up everything first, since I was pretty sure something was going to go wrong. It had to!
Time to reinstall Windows, AGAIN. :(
|
|
|









