ARCHIVES
August 2011
July 2009
May 2009
April 2009
March 2009
February 2009
January 2009
December 2008
November 2008
August 2008
July 2008
June 2008
May 2008
March 2008
February 2008
January 2008
November 2007
CONTACT
|
| About this blog: Computers hate me. They really do. Every time I try to do something unusual like add new hardware, something is guaranteed to go wrong. I decided to start writing about my constant problems so that someone else might benefit from my experiences - or at least laugh at them! |

I've gone against my previous promise to never buy Seagate again, but it was for a good reason: I wanted to mirror (RAID1) an existing Seagate drive. I've seen instances where a Seagate and WD drive of supposedly identical capacity had a slightly different number of sectors, so I played it safe and bought another Seagate. If I'd bought WD and it had even one less sector than the Seagate, mirroring would not have worked. (It may have been the other way around, with the WD drive having more - but I didn't want to risk it.)
I've bedded the ex one last time, but that's it. Absolutely no more, Seagate!
|
|
With the latest HD failure now swapped for a new one I've written a simple program that creates enough 1GB files to fill the drive, then runs in a loop that randomly chooses a file, seek point, block size, and whether to read or write data. It runs for 7 days.
It's not perfect but the idea is to give a new HD a bit of a thrashing to see if it's going to die as youngun - rather than keeping it as a spare in its factory packaging until needed...
|
|
I was watching TV in the family room when I heard the dreaded chirp signalling that a RAID array was degraded.
Further investigation revealed: "Error: AMNF 32 sectors at LBA = 0x001a3060 = 1716320" (AMNF appears to be Address Mark Not Found)
Both short and long drive tests failed:
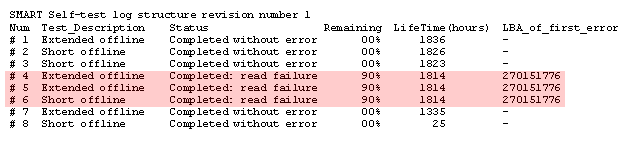
A subsequent zero fill seems to have quietly hidden the bad area - as you can see above further self tests succeed - but SMART was now showing 5 uncorrectable errors:
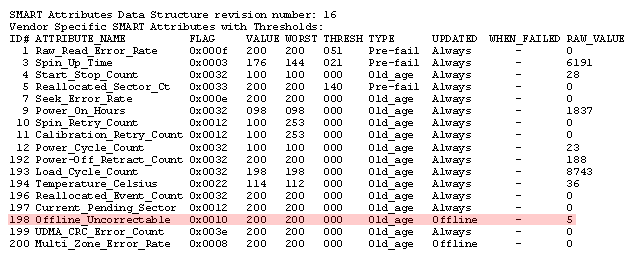
I opened a ticket with Western Digital asking whether this sudden increase (and also non zero count) of uncorrectable errors in a drive that had been powered on for only 2 1/2 months was sufficient to return the drive. In the meantime, I wrote random junk to the drive (FreeBSD: dd if=/dev/random of=/dev/ad10 bs=65536 in an endless loop) to "cover" the existing data and also see if I could evoke further errors. I received an affirmative response from WD a few days later, so I returned to my retailer armed with printouts of the ticket and data from smartctl. It was a little touch and go for a couple of minutes, but I had it replaced with a new one.
|
|
|