ARCHIVES
August 2011
July 2009
May 2009
April 2009
March 2009
February 2009
January 2009
December 2008
November 2008
August 2008
July 2008
June 2008
May 2008
March 2008
February 2008
January 2008
November 2007
CONTACT
|
| About this blog: Computers hate me. They really do. Every time I try to do something unusual like add new hardware, something is guaranteed to go wrong. I decided to start writing about my constant problems so that someone else might benefit from my experiences - or at least laugh at them! |

3 seals visible - the middle one is not quite right | 
Top: normal seal. Bottom: suspect seal. |
I noticed something unusual when I was shifting HDs around for better air circulation - all of the drives have their seal looking neat and perfect, except for one. At first I thought it was dust, but when you look at it closely it's obvious that it's imperfections in the seal. Kind of worrying. Perhaps this will be the next drive to fail...
|
|
Woken up by a phone call at 1am I went into the computer room to look up the caller ID number on Google, so I could figure out if it was a business that I could call back and have a grumble at. (If it's a teen girl secretly calling her boyfriend then I don't really want to wake the rest of the family by calling the number back directly. :-D )
This is what greeted me when I switched my screen on:
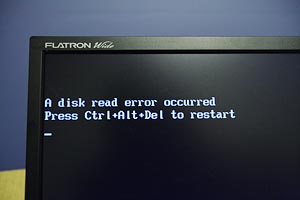
I recently changed XP SP2 to not restart on a fatal error so I thought this was one of its panics. I did think it was a little odd because normally Windows errors are a lot more verbose, but still without really telling you much. By chance when cloning the drive (just to be safe) I noticed that this exact string appears very early in the data on disk, as part of the low level boot loader. So it seems likely my computer did reboot for some reason, then failed at a very early part of the boot stage.
A short then extended drive test passed with no errors. After that, a peek inside the case revealed I have one of the dreaded "COMAX" SATA cables connected to the drive. I also noticed the UDMA CRC Error Count SMART value has increased, which means a communication problem between the drive electronics and the motherboard SATA controller (not a mechanical error). Stupid crappy cables. I tried to buy some of the yellow Gigabyte type the other day but the store only had the red COMAX type. Glad I didn't waste my money...
I had a lot of problems with Intel Matrix RAID declaring that drives had failed (with no further detail provided), then subsequent testing showed they were fine. I bet it was the cables that caused all of those issues. The only question is, if they're really that bad then why isn't anyone else having problems? They've been supplied with every ASUS motherboard I've purchased so they're not exactly an obscure product.
I can't wait to buy a bunch of the yellow cables and get rid of the COMAX ones for good.
|
|
Some users may not be aware that FreeBSD will unconditionally panic if a drive that is mounted goes away for some reason. This includes unplugging removable devices such as a USB stick. The entire OS instantly ceases to operate, like a Windows blue screen.
I wandered into the office and noticed a screen full of WRITE_DMA TIMEOUT error messages about a particular drive. Checking of logs on other machines showed the server had been non responsive for at least 4 hours. Ctrl-Alt-Del didn't do anything (it normally forces a reasonably graceful shutdown) so I tried one last thing before hitting reset: unplugging the drive. I figured because it was part of a mirror that FreeBSD would detect it as failed, disconnect it from the mirror, and happily continue with what it was doing.
Unfortunately, I was wrong! It panicked and locked up with a very loud continuous beep. Fun at 5:30am when your family is asleep...
I suspect it's due to dodgy SATA cables: I have found the red "COMAX" type supplied with Asus motherboards to be quite unreliable, often throwing up CRC errors under FreeBSD (or in the case of Windows + Intel Storage Matrix, disconnecting the drive from the array, or even rebooting). I haven't had a single problem with the yellow locking type supplied with Gigabyte motherboards, but I'd run out of them when I installed this drive a couple of days ago. :(
The question still remains why issues on a single SATA port have caused the entire server to grind to a halt, and why gmirror hadn't just disconnected the drive from the array after 4 hours worth of DMA timeouts. It's not the first time I've seen a single faulty drive in a mirrored array end up killing the whole server...
UPDATE: I swapped out a yellow/Gigabyte cable from a box with a disk caddy that wasn't in use, but accidentally unplugged the wrong motherboard port... one which was connected to an active HD rather than an empty caddy receptacle. Oops. However, FreeBSD reported "GEOM_MIRROR: Device gm0: provider ad8 disconnected" and continued... as you would expect. I wonder why the same thing didn't work on the other server?
|
|
I noticed that my database server was mainly doing reads for (random) index lookups, with the occasional bit of writing. Because of the random nature of access my server was being held back by HD I/O speed; I'd been thinking about moving to a faster drive, a SATA VelociRaptor or perhaps even coughing up for an SAS solution. Cost was an issue, particularly because with my bad luck my storage pretty much has to be redundant (that means at least two drives on RAID1).
After some thought, I came up with a novel idea: mirror the VelociRaptor with a standard drive, and force FreeBSD's gmirror to read only from the VelociRaptor. In effect, this RAID1 array provides a high speed random read with a "standard" speed write. The cost per gig is about $AUD1.50 versus $AUD2.50 if I'd just used two VelicoRaptors. (Now compare this to $AUD0.46 per gig if I'd just used standard drives.....)
A real world example:

ad8 is a 300GB VelociRaptor, ad10 is a standard 320GB drive. Read requests (red) go only to the busy VelociRaptor while the less frequent/frantic write requests (green) are mirrored over both drives.
|
|
I've discovered the hard way that a cheap 2 port PCI express card with a JMicron JMB363 chip on it hard locks FreeBSD 7.0 amd64 - usually within a minute of starting my disk testing (thrashing) program. This is a true hard lock: everything frozen, no keypresses work, even the reset button does nothing for a few moments... and then the computer powers off! (I've never seen this behaviour before, I presume it must be some failsafe circuit that realises things are FUBAR and the only option is to shut down.)
I suspect it's probably an AHCI quirk. The card's BIOS doesn't have any option to enable or disable AHCI in hardware, so instead I tried using FreeBSD's atacontrol to force the drives on that controller into SATA150 (and hopefully non AHCI) mode. It refuses to make any change, stubbornly reporting that the mode is (still) set to SATA300.
As a last resort, I examined and hacked the kernel source:
/usr/src/sys/dev/ata/ata-chipset.c:
- { ATA_JMB363, 0, 2, 1, ATA_SA300, "JMB363" },
+ { ATA_JMB363, 0, 2, 0, ATA_SA150, "JMB363" },
On boot it's still reported as an AHCI compatible controller, and the attached drives are reported as SATA300, but it's no longer crashing the comp: the disk testing program successfully ran for over an hour, which is about a hundred times longer than it's previously lasted.
One other option that occurred to me was to jumper the drives to force SATA150 mode (first thing I do with a new Seagate is pull out the factory jumper), but unfortunately I had no idea where or if I'd stored the minature jumpers.
The software fix seems to be working. Fingers crossed.
|
|
The VelociRaptor HD is actually a slightly bulky 2.5" drive permanently mounted inside a 3.5" heatsink. Although the dimensions of the device are identical to a full sized 3.5" drive, the SATA power and data connectors are not in the same position as a standard drive. This means that if you have a caddy or hot swap system with a rigid, fixed position connector you won't be able to use a Velociraptor. If it's connected via (flexible) cables there's no issue. In addition, the data connector is not a locking type. Just a heads up for people who may not be aware.

A VelociRaptor (at top) with three standard 3.5" drives below.
Note the different offset of the SATA connectors.
UPDATE: WD now offer a "backplane ready" version with the connectors in the right place, and a 2.5" form factor version (minus the big heatsink). The original version still seems to be the easiest to find, though.
|
|
I've been looking through my notes trying to figure out the trail of failures. The earlier Seagate 300GB SATA model saga is a particularly complex series of events. I think I've got it right now:
Of the original 4 x 300GB ST3300831AS drives purchased in late 2005, all 4 failed (one was DOA, one triggered a SMART event within 24 hours, the other two lasted 18 months longer). 2 were replaced with new drives by the retailer, 2 were replaced with reconditioned drives by Seagate. One of the reconditioned drives was faulty out of the box! This was replaced and then yet another drive failed.
Eventually the whole set of ST3300831AS drives (I think by this point they were all reconditioned replacements, none original) was "upgraded" by Seagate to 4 x ST3300620AS drives, but unfortunately they were also reconditioned. I had misunderstood Seagate's offer and thought they were supplying me with new drives, given the problems I'd been through. One of these "newer" drives failed in January 2008; I'd had enough so they were all shelved soon afterwards. Just for fun I recently put them into a server and checked their SMART values: all are showing uncorrectable read errors.
If I've done my notes correctly that brings the totals of wanting to buy FOUR drives to: 6 new drives, 6 recos, 7 failures. (A 58% or 175% failure rate, depending on your viewpoint.)
Don't forget the remaining recos are showing errors so if I dared actually use them they would probably eventually fail as well.
There's also the two USA based servers which had Seagate drives fail shortly after they were commissioned for me, mentioned in earlier posts.
WD is a bit easier: out of a total of 10 x 750GB WD7500AAKS / WD7500AACS drives purchased, two have failed, and were replaced with new drives. I also have 7 x 320GB and 3 x 80GB WD drives which are going fine (touchwood)
Hopefully this gives you an idea of the very bad luck I've had. The 750GB WD failures are somewhat expected because they work fairly hard in a database server, but the 300GB Seagates were installed in a desktop that hardly does anything disk intensive... apart from rebuilding RAID arrays every time I had to replace a failed disk. :-D
|
|
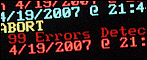
A new server that I ordered from a USA based webhost had one of its Seagate drives fail during install; now the replacement (which was supposed to be new) is showing 99 reallocated sectors and a power on hours value that suggests it's newish, but certainly not new.
There's no absolute failure, but 99 reallocated sectors after being powered on for a month is definitely a worry. There's also the fact that the webhost's supplier was supposed to send him a new drive, not one with a POH value of 643.
Until recently my bad luck with Seagate drives was limited to local boxes within arms reach, unfortunately it now seems to be spreading to my USA hosted servers. This is the second time in about 6 weeks that a Seagate drive in a newly ordered USA server has looked a little sick, or failed... and that's even before the server is doing anything useful.
|
|
I recently installed an additional HD and an additional 4GB RAM (total 8GB) into one of my servers. Since then it's locked up 4 times. It's probably the RAM: sometimes the comp won't reset properly (screen clears, HD light blips, but POST never starts - have to power off then on again). Could be the HD though.
Each pair of RAM sticks are the same model, but they were purchased a few months apart. FreeBSD 7.0 has no problems with 8GB of the same model of memory in another server, but that's using another motherboard and chipset. It could be faulty RAM, or it may be some sort of incompatibility quirk.
Currently running a memory test using Memtest86+, unfortunately the basic tests haven't found any problems so far. Hopefully with time and more rigorous testing there will be a smoking gun reported, so I can exchange the sticks...
UPDATE: with the suspect sticks in the "primary" set of slots Memtest86 GPF'd (FreeBSD's panic also reported a GPF), in the secondary slots there were unfortunately zero errors reported. I've swapped the suspect sticks into another server that has been set to do a lot of data shuffling that will use almost all available memory. If it crashes then the sticks are going back. If the first server still crashes even with the suspect sticks swapped out then I have a bigger problem.
UPDATE #2: the second server crashed. Sticks are going back tomorrow.
|
|
|