ARCHIVES
August 2011
July 2009
May 2009
April 2009
March 2009
February 2009
January 2009
December 2008
November 2008
August 2008
July 2008
June 2008
May 2008
March 2008
February 2008
January 2008
November 2007
CONTACT
|
| About this blog: Computers hate me. They really do. Every time I try to do something unusual like add new hardware, something is guaranteed to go wrong. I decided to start writing about my constant problems so that someone else might benefit from my experiences - or at least laugh at them! |
I ordered a server from a USA based webhost, installed smartctl to check the SMART values of the two drives, and noticed with some concern that they were not new - they'd been powered on about 7 months. I expressed this concern to the host who said that used drives are better because they have "history."
At this point I could only giggle nervously, because I knew what could happen, given my luck... and it did. The reallocated sector count on one drive climbed from 1 to 308 within a couple of days; the second drive went from 1 to 5, and a short test failed with a read error.
The drives were quickly replaced but unfortunately they're also Seagate.
On the plus side, this event motivated me to figure out the config file for smartd, so I'm now emailed whenever a critical SMART value changes on any HD in my various servers (I currently have 5 local and 4 remote.)
Incidentally, these used drives had content from another customer on them... some sort of keyword based comment spamming tool by the looks of it. This isn't really an acceptable situation, allowing a new customer to see someone else's data. Whenever I hand back a server I always do a zero fill of the drive; you never know who's going to see it next.
|
|
After the numerous stability problems I've had over the past 2 1/2 years (plus a few hardware glitches) since I started using Intel Matrix RAID I'm toying with the idea of canning local RAID and instead storing all of my data on a dedicated (and stable) NAS box.
My first experiment with ProNFS v2.9 didn't go too well.
I mounted the remote volume without any trouble, and was able to copy some test files without any issue. NTbackup sped along at about 200kbytes/sec (that is kiloBYTES per second) until I fiddled with some of the NFS settings and managed to get it to about 3Mbytes/sec. I then started a "live" file copy of my 500GB of data sitting on the local RAID5 array to the NFS mount, and went to bed.
Came back this morning to a dark screen - absolutely nothing showing, and the comp was hard locked. The FreeBSD server only showed 18MBytes worth of data had been transferred to the mount.
Since then the comp has crashed twice again, each within 5 minutes of reboot. First time was a spontaneous reboot, second was a blue screen and lockup.
Uninstalling ProNFS for now since that seems to be the likely suspect.
|
|
Although I've copied the data from the old RAID5 array to the new RAID1 array I'm still not 100% confident it's safe. I started a final backup of the RAID5 contents to a file, which I intended to upload to one of my FreeBSD servers - just in case I discover in 3 days time that half the files xcopy'd were corrupt.
As usual, nothing goes smoothly.........
NTbackup froze at about 350GB processed out of about 480GB total; both the elapsed and remaining times were not changing. When I discovered this I decided to leave it for a couple more minutes to be absolutely sure of this, but then everything else died: Seamonkey went "(Not Responding)", the hourglass replaced the mouse pointer, C-A-D did not bring up the task manager (although I did notice it caused the HD light to flicker each time I tried it). I had to press reset as there was no way to action a shutdown. Surprisingly, on reboot the Intel Matrix Storage Console decided to verify the RAID5 array, even though it was the RAID1 array that was being written to.
I've upgraded the Intel Matrix drivers from 7.5 to 7.8, as there's a specific reference to that version fixing a crash problem, and I'm trying the backup again.
|
|
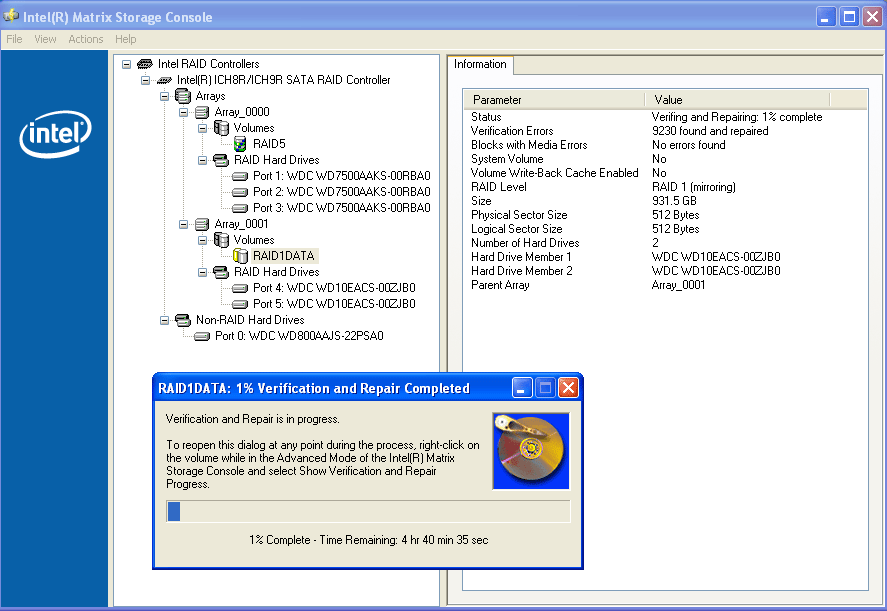
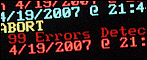
Here's a RAID1 array that I created a few hours ago, then xcopy'd all files from an existing RAID5 array (I'm changing from a 3 x 750GB RAID5 to a 2 x 1TB RAID1). I decided to run a verification to force all sectors to be read, and there are already an alarming number of verification errors being reported. Under RAID1 I presume means that the data on the two disks is not identical - which shouldn't be happening on a fresh array! The screen cap was taken at 1% and it was showing 9,230 errors; it's now at 3% and reporting 47,148 errors.
Earlier, when I was attempting to backup then restore using ntbackup, the restore froze with the HD LED light remaining on. I could switch between windows but the comp was otherwise non responsive. After a reboot one of the drives started thrashing away, even though the HD light was not going on. This phantom thrashing continued for several minutes - with the comp idle - until I did a shutdown. A subsequent diagnostic test does not reveal anything.
Now, the RAID1 array has apparent errors, even though the array has been destroyed, recreated, and reformatted since the freeze. There's either something very wrong with one of the drives, or some sort of bug with Intel's Matrix RAID driver. The only other explanation I can think of is that for some reason mirroring does not work in safe mode (which I used when copying the files) - the driver was definitely loaded, since the source was a RAID5 array.
UPDATE: the comp blue-screened a few minutes after I completed the original post.
|
|
Realised tonight that AHCI cannot be enabled per drive - it's all or nothing in the Gigabyte EX38-DS4 BIOS. Unfortunately the SATA to CompactFlash card adapter I have doesn't seem to support AHCI; the drive is not detected. I'm not really sure how much benefit AHCI would provide in this instance (a 5 x 750GB RAID3 array used for NAS and backups) but I've chosen to be conventional and install the OS on a standard mechanical drive, rather than fool around with CF and lose that potential benefit for every SATA device.
|
|
|